使用langchain-chatchat搭建安全知识库
使用langchain-chatchat搭建安全知识库
背景
LLM大环境下,无论开源模型或者商业模型,都是使用通用预料进行训练的,一方面是缺乏对垂直行业的支持,另一方面是数据的机密性导致无法开源数据。针对这种情况,我们尝试使用langchain-chatchat+主流开源大预言模型来搭建私有的安全知识库。
主要目的是为了让网络安全行业知识更加易于使用和查找,利用自然语言处理技术对每个模块中的关键词、短语进行标注,建立起一个语义化的知识库。用户可以通过简单的关键词搜索+语义组合搜索来快速找到所需信息,提高信息获取的效率和准确性。另外,还可以识别用户的意图,帮助用户发现可能感兴趣的内容,从而提高用户体验。通过这种方式,可以建立一个全面、权威的网络安全行业知识库,为用户提供更好的网络安全保护服务。
注意:以下内容适用于2023年10月16日前,由于目前技术不稳定,每天都会发生技术迭代,请酌情参考。有问题给我留言即可。
原理
加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
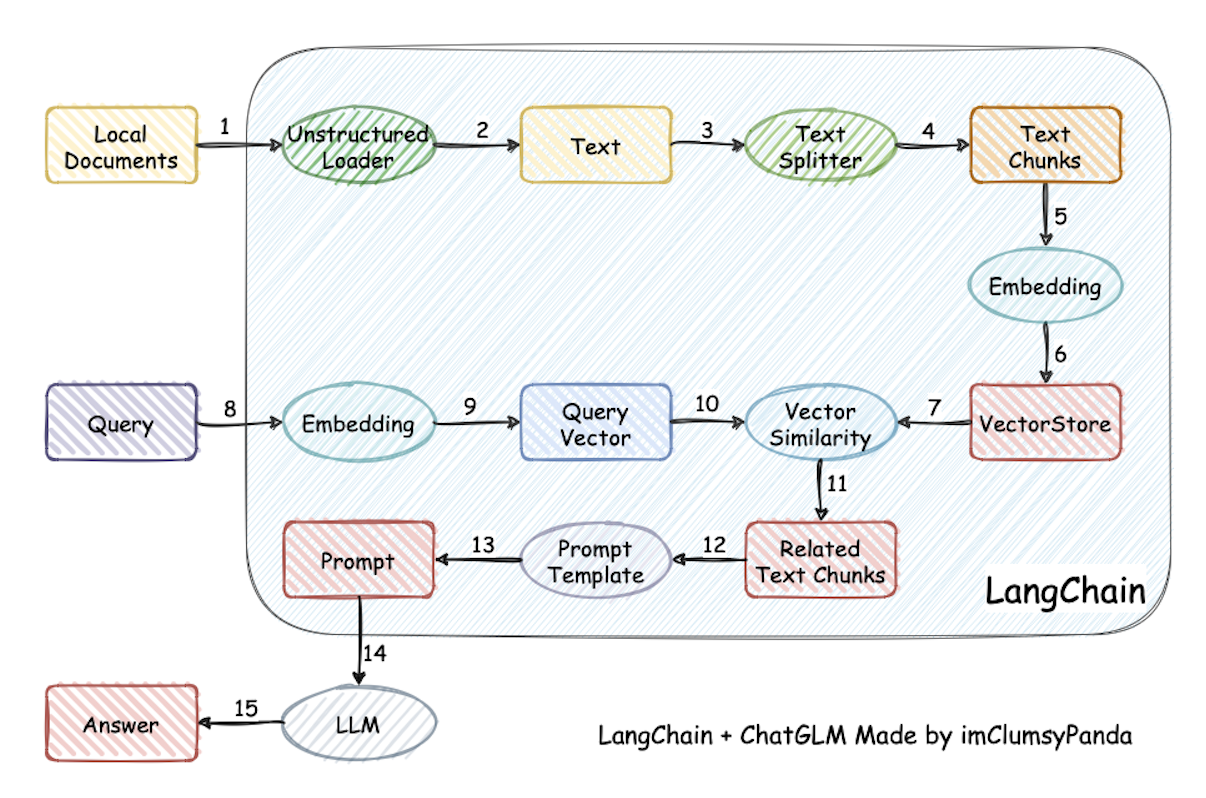
文档视角: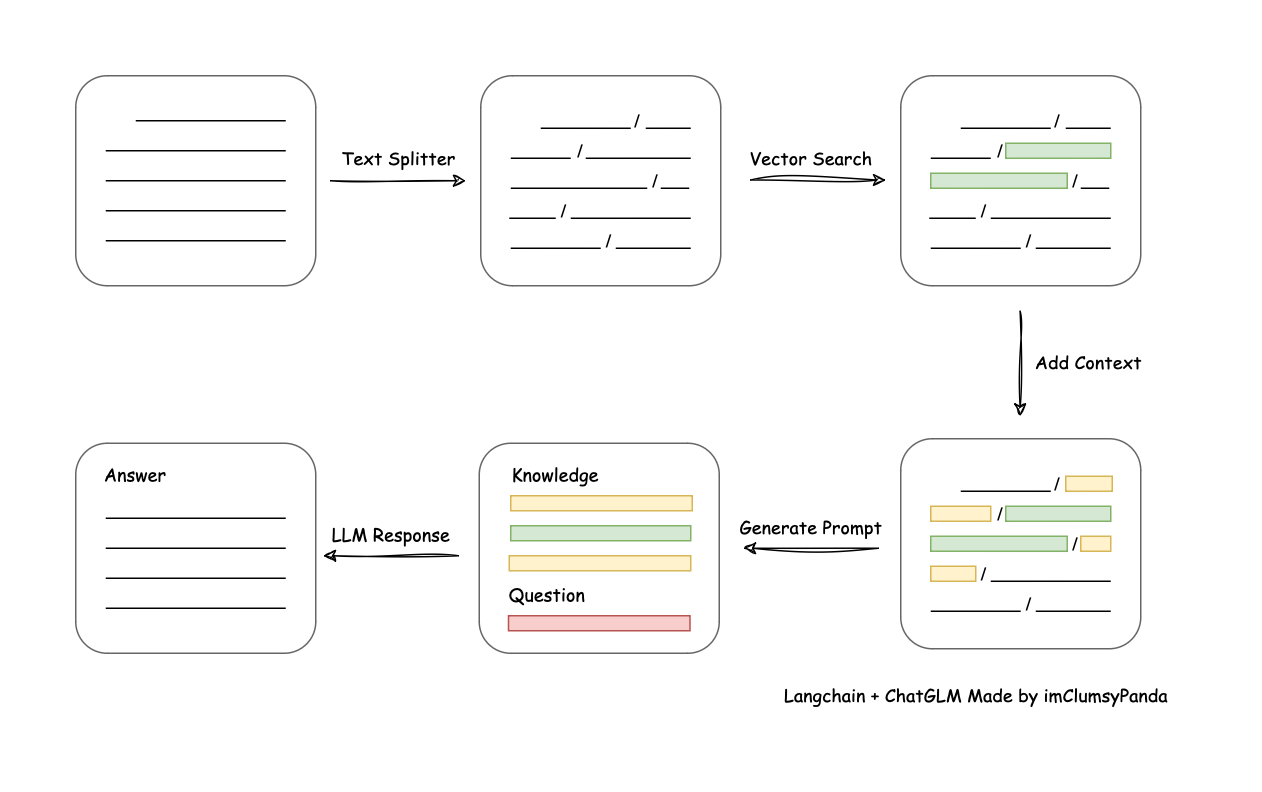
准备
1、心仪的开源大语言模型,模型自行到huggingface上下载,我们尝试了baichuan2-78和qwen-7b效果都不错,向量模型推荐bge-large-zh-v1.5。
2、丹炉,这个自己准备了,环境可以参考我上一篇文章,或者自行搭建。
3、相关知识库,我们这里使用常见的网络安全标准来测试。
安装
使用conda搭建环境
克隆项目
1 | |
进入项目目录,使用已下命令安装依赖环境
1 | |
配置
在项目目录下,复制configs目录下所有.example的文件为.py,如:复制模型相关参数配置模板文件 configs/model_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 model_config.py。
在开始执行 Web UI 或命令行交互前,请先检查 configs/model_config.py 和 configs/server_config.py 中的各项模型参数设计是否符合需求:
模型配置
打开configs/model_config.py
- 请确认已下载至本地的 LLM 模型本地存储路径写在
llm_model_dict对应模型的local_model_path属性中,如:1
"Qwen-14B-Chat": "/data/models/Qwen-14B-Chat", - 请确认已下载至本地的 Embedding 模型本地存储路径写在
embedding_model_dict对应模型位置,如:1
"bge-large-zh-v1.5": "/data/models/bge-large-zh-v1.5",
其他配置(高级)
如果需要指定端口,我这里由于是在容器中运行,需要指定端口,我这里需要指定80,
修改webui端口信息,configs/server_config.py 将端口修改成 80。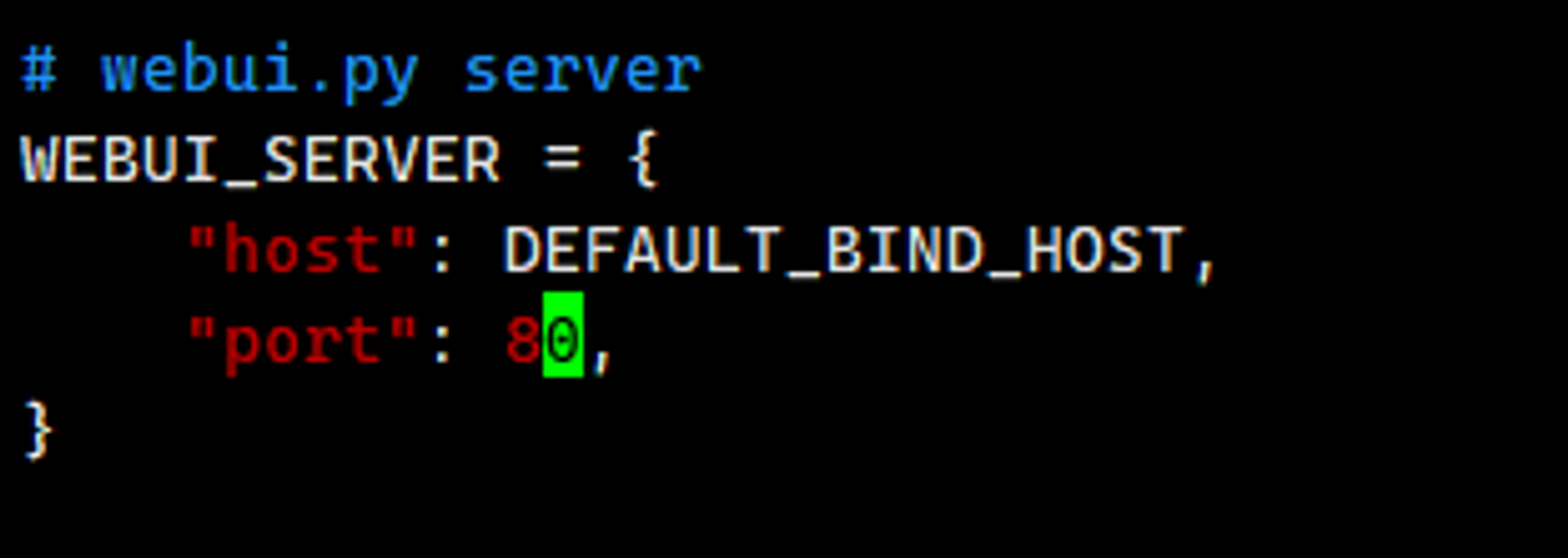
知识库初始化与迁移
当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库,建议在执行操作前备份您的知识文件。
- 如果是从
0.1.x版本升级过来的用户,针对已建立的知识库,请确认知识库的向量库类型、Embedding 模型与configs/model_config.py中默认设置一致,如无变化只需以下命令将现有知识库信息添加到数据库即可:1
python init_database.py - 如果是第一次运行本项目,知识库尚未建立,或者配置文件中的知识库类型、嵌入模型发生变化,或者之前的向量库没有开启
normalize_L2,需要以下命令初始化或重建知识库:
1 | |
多卡加载
项目支持多卡加载,需在 startup.py 中的 create_model_worker_app 函数中,修改如下三个参数:
1 | |
其中,gpus 控制使用的显卡的ID,例如 “0,1”;num_gpus 控制使用的卡数;max_gpu_memory 控制每个卡使用的显存容量。

这里选择baichuan2-7b,勉强能跑起来。
运行
运行命令,为了避免无法使用多卡运算,手动指定
1 | |
访问对应端口,进入langchain-chatchat界面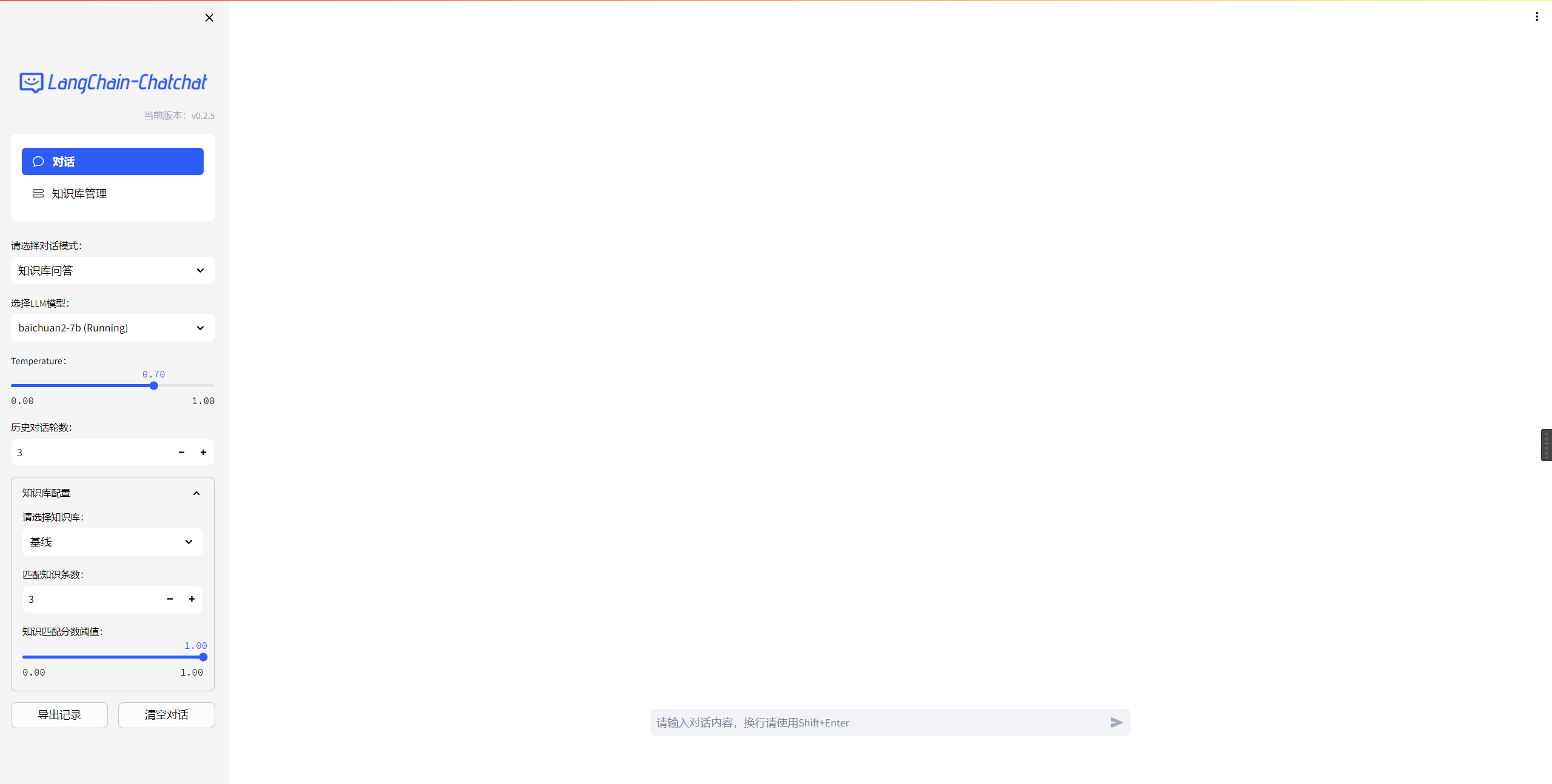
点击知识库管理,选择新建知识库,知识库名称根据实际情况填写,对于向量库类型和向量模型,没有需求使用默认即可,我这里选用了bge。如果配置没问题,点击新建即可。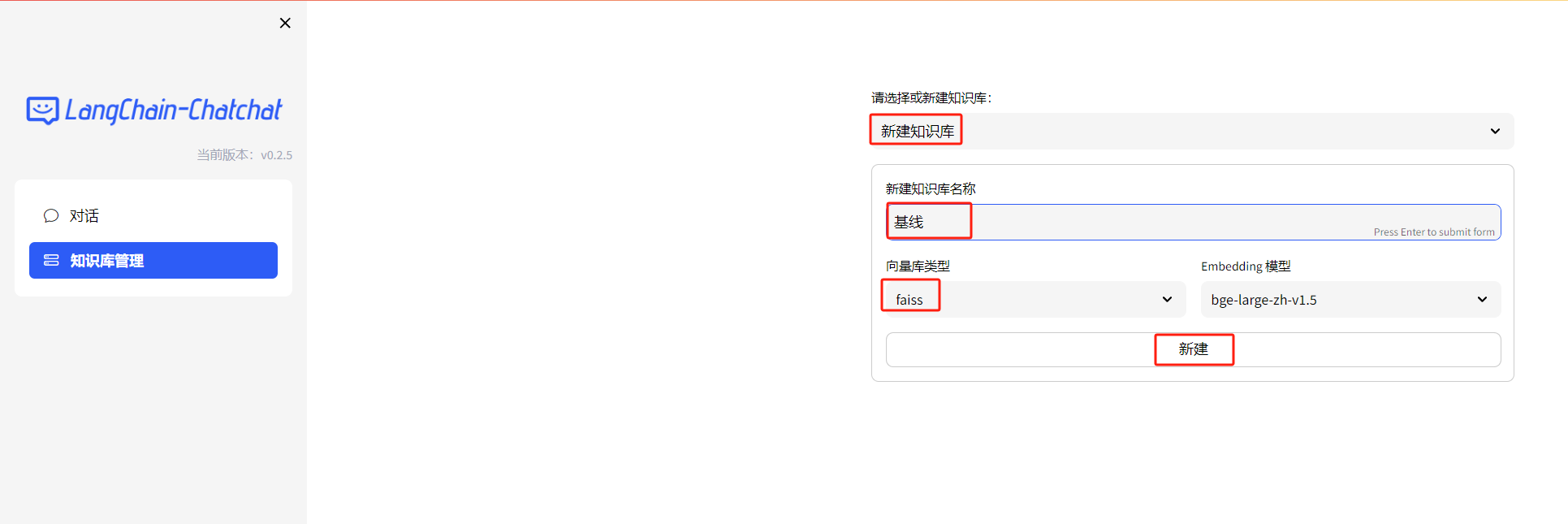
创建完知识库,进入知识库配置界面,拖拽或者上传正确格式的文本文件,单个文件限制在200M以内,文件格式包括:HTML, MD, JSON, CSV, PDF, PNG, JPG, JPEG, BMP, EML, MSG, RST, RTF, TXT, XML, DOCX, EPUB, ODT, PPT, PPTX, TSV, HTM,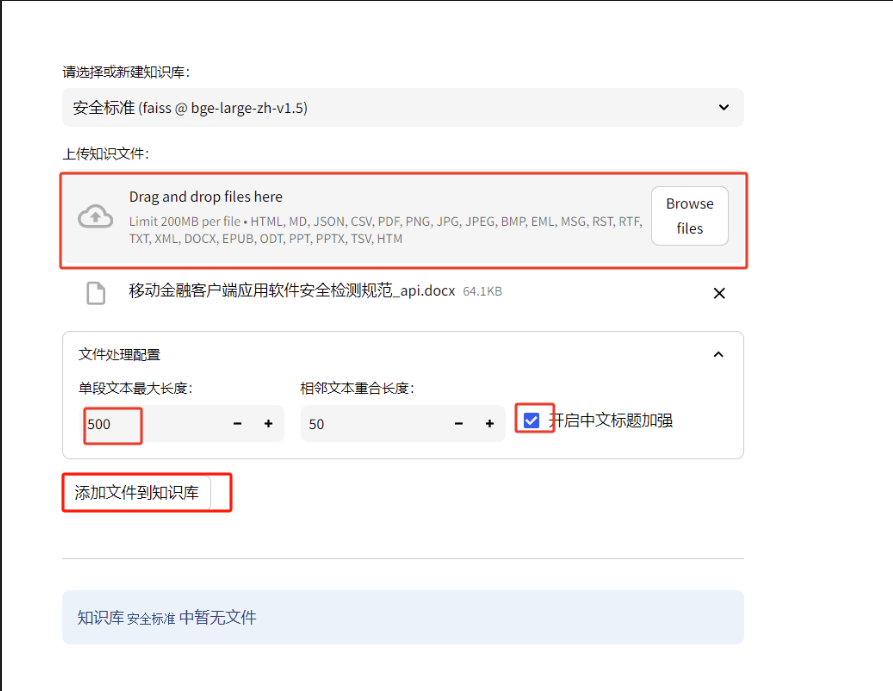
其中文件处理配置,单段文本最大长度默认为250,个人感觉比较短,目前配置成500,并且开启了中文标题增强,点击添加文件到知识库。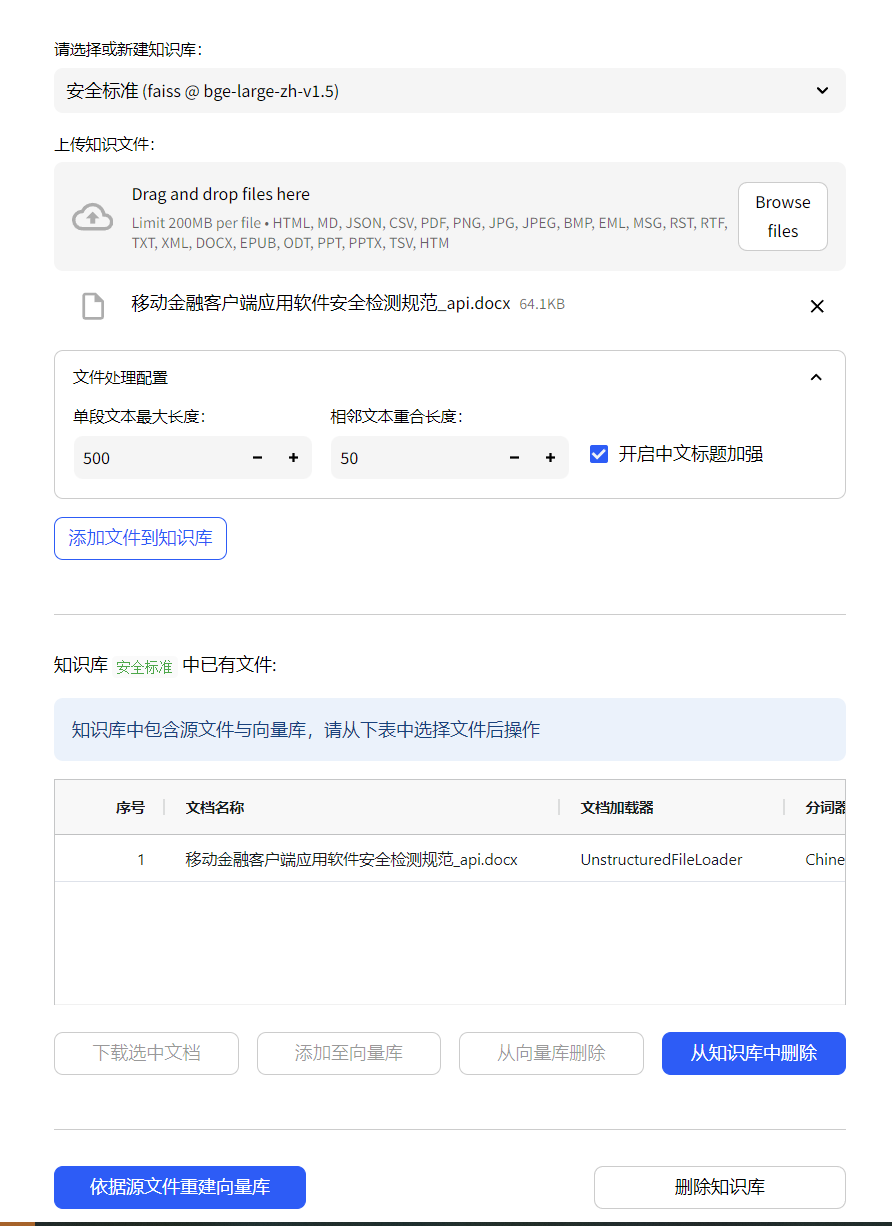
如果文件没有问题,会自动上传进行向量切割。
如果有错误,处理完成后,也可以手动选择文档,手动添加到向量库。
注意:这里文档是可以下载,如果涉及敏感文档,注意审查,也可以二开,关闭文档下载。
数据向量化,瓶颈在cpu上。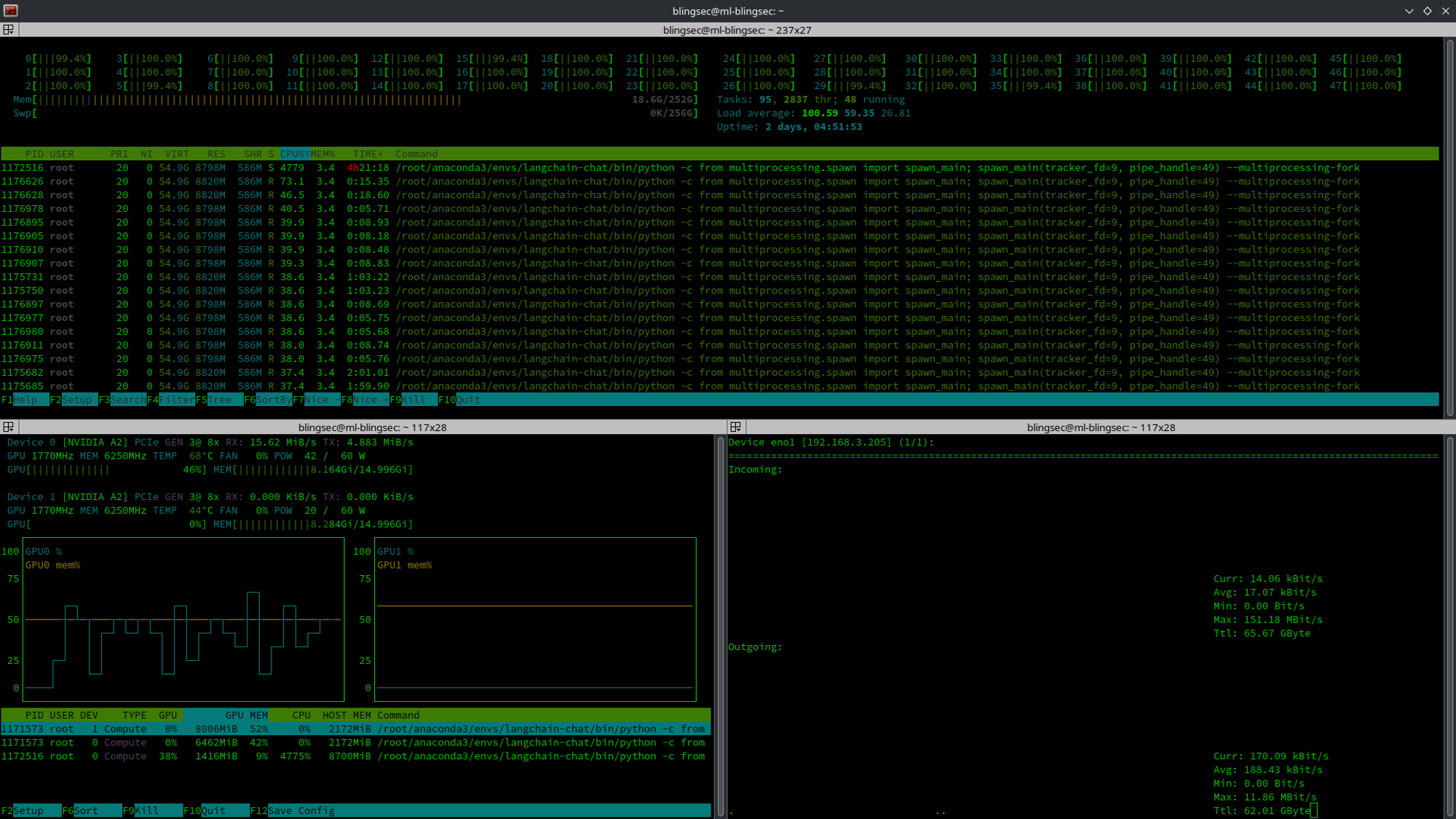
错误
RuntimeError: shape ‘[3, 32, 128]’ is invalid for input of size 15360
这个是qwen-14b貌似不兼容,有issus,目前无法解决
执行 python cli_demo.py过程中,显卡内存爆了,提示 “OutOfMemoryError: CUDA out of memory”
将 VECTOR_SEARCH_TOP_K 和 LLM_HISTORY_LEN 的值调低,比如 VECTOR_SEARCH_TOP_K = 5 和 LLM_HISTORY_LEN = 2,这样由 query 和 context 拼接得到的 prompt 会变短,会减少内存的占用。或者打开量化,请在 configs/model_config.py 文件中,对 LOAD_IN_8BIT参数进行修改。
这个是官方给的建议,我只是遇到了大模型加载爆显存,通过更换模型来处理的
timeout
部分情况会自动加载hugging face数据,但是显示连接超时,可以在运行之前指定一下代理地址,比如:
1 | |
libgl.so.1 cannot open shared object file no such file or directory
手动安装以下库,重启web服务即可。
1 | |
评估
评估测试,这里的问题为:我设计了一个静态密码,有哪些安全要求
效果还是挺不错的。
如果直接使用pdf,会有一些脏数据,这个是由于网络安全发文中的目录和页眉页脚脏数据导致的。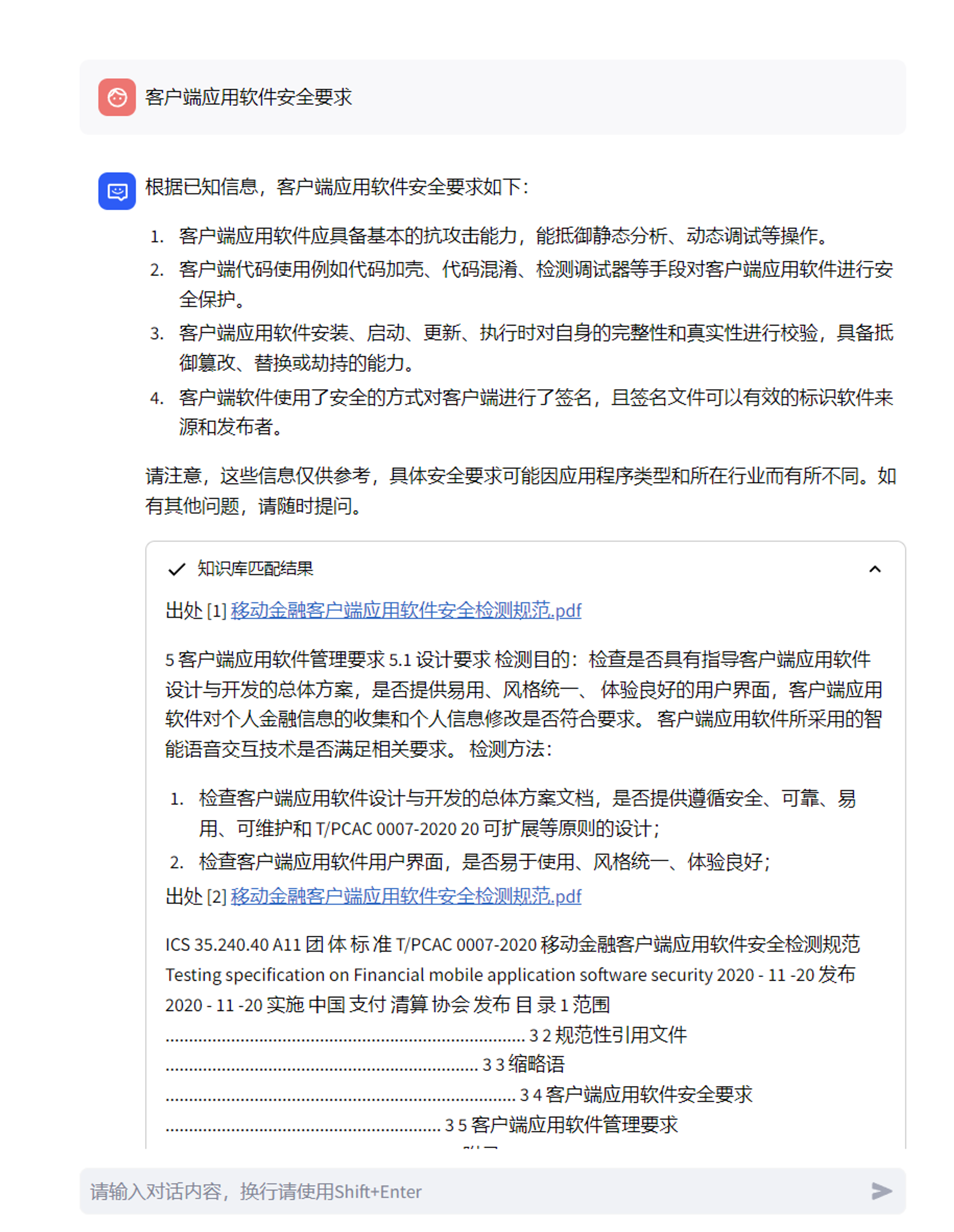
可以将pdf转成docx格式,手动或者自动去除脏数据,然后进行训练,效果会更好,以下是同一个问题,docx和pdf对比结果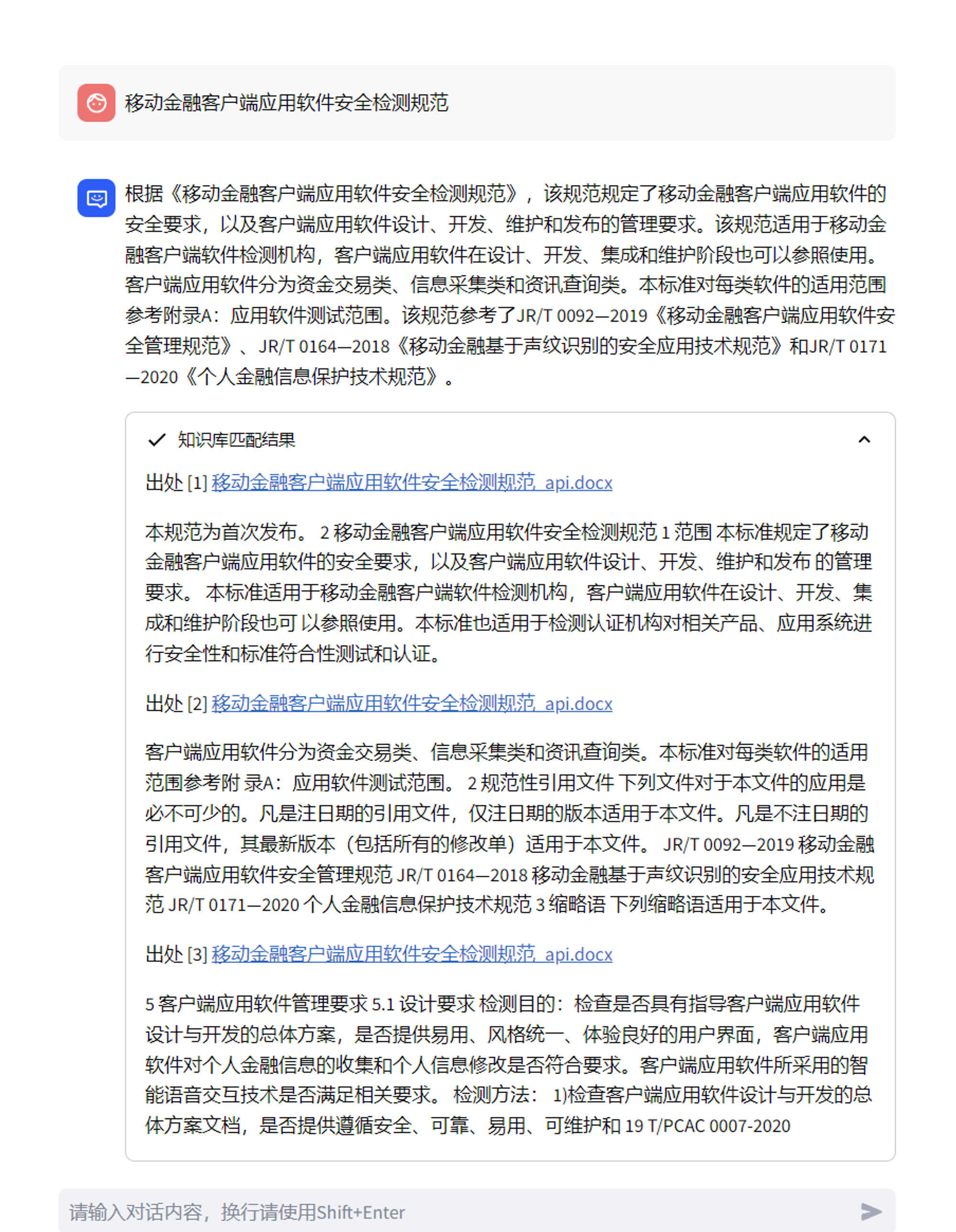
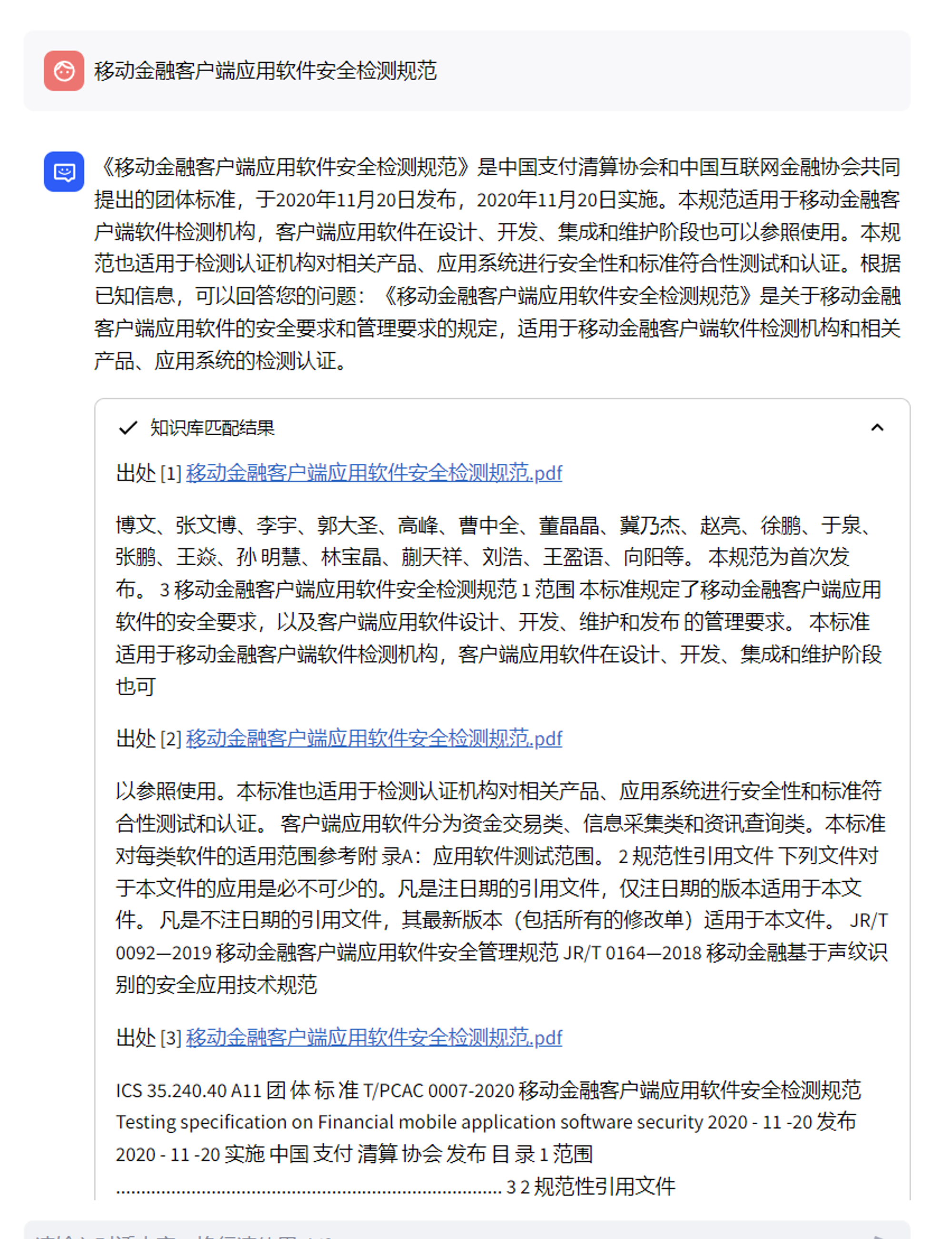
总结
1、辅助检索目前效果可以,但是大差不差,这个仁者见仁智者见智。
2、如果知识库有很庞大的规模 默认的Faiss 可能会有点吃力 ,需要使用 milvus 向量数据库。
3、优先使用md或者txt语料,docx要优于pdf,准确的语料是成功的基石。
4、好的丹炉事半功倍,好的梯子让人愉悦。
参考
- https://github.com/chatchat-space/Langchain-Chatchat【Langchain-Chatchat】
- https://zhuanlan.zhihu.com/p/651189680【Langchain-Chatchat + 阿里通义千问Qwen 保姆级教程 | 次世代知识管理解决方案】
- https://www.cnblogs.com/shengshengwang/p/17747781.html【Langchain-Chatchat项目:1.2-Baichuan2项目整体介绍】
- https://hksanduo.github.io/2023/10/13/2023-10-13-ml-env/【基于Docker搭建机器学习环境】
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!