# ~/.bashrc: executed by bash(1) for non-login shells. # see /usr/share/doc/bash/examples/startup-files (in the package bash-doc) # for examples
# If not running interactively, don't do anything [ -z "$PS1" ] && return
# don't put duplicate lines in the history. See bash(1) for more options # ... or force ignoredups and ignorespace HISTCONTROL=ignoredups:ignorespace
# append to the history file, don't overwrite it shopt -s histappend
# for setting history length see HISTSIZE and HISTFILESIZE in bash(1) HISTSIZE=1000 HISTFILESIZE=2000
# check the window size after each command and, if necessary, # update the values of LINES and COLUMNS. shopt -s checkwinsize
# make less more friendly for non-text input files, see lesspipe(1) [ -x /usr/bin/lesspipe ] && eval"$(SHELL=/bin/sh lesspipe)"
# set variable identifying the chroot you work in (used in the prompt below) if [ -z "$debian_chroot" ] && [ -r /etc/debian_chroot ]; then debian_chroot=$(cat /etc/debian_chroot) fi
# set a fancy prompt (non-color, unless we know we "want" color) case"$TERM"in xterm-color) color_prompt=yes;; esac
# uncomment for a colored prompt, if the terminal has the capability; turned # off by default to not distract the user: the focus in a terminal window # should be on the output of commands, not on the prompt #force_color_prompt=yes
if [ -n "$force_color_prompt" ]; then if [ -x /usr/bin/tput ] && tput setaf 1 >&/dev/null; then # We have color support; assume it's compliant with Ecma-48 # (ISO/IEC-6429). (Lack of such support is extremely rare, and such # a case would tend to support setf rather than setaf.) color_prompt=yes else color_prompt= fi fi
if [ "$color_prompt" = yes ]; then PS1='${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u@\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$ ' else PS1='${debian_chroot:+($debian_chroot)}\u@\h:\w\$ ' fi unset color_prompt force_color_prompt
# If this is an xterm set the title to user@host:dir case"$TERM"in xterm*|rxvt*) PS1="\[\e]0;${debian_chroot:+($debian_chroot)}\u@\h: \w\a\]$PS1" ;; *) ;; esac
# enable color support of ls and also add handy aliases if [ -x /usr/bin/dircolors ]; then test -r ~/.dircolors && eval"$(dircolors -b ~/.dircolors)" || eval"$(dircolors -b)" aliasls='ls --color=auto' #alias dir='dir --color=auto' #alias vdir='vdir --color=auto'
alias grep='grep --color=auto' alias fgrep='fgrep --color=auto' alias egrep='egrep --color=auto' fi
# some more ls aliases alias ll='ls -alF' alias la='ls -A' alias l='ls -CF'
# Alias definitions. # You may want to put all your additions into a separate file like # ~/.bash_aliases, instead of adding them here directly. # See /usr/share/doc/bash-doc/examples in the bash-doc package.
if [ -f ~/.bash_aliases ]; then . ~/.bash_aliases fi
# enable programmable completion features (you don't need to enable # this, if it's already enabled in /etc/bash.bashrc and /etc/profile # sources /etc/bash.bashrc). #if [ -f /etc/bash_completion ] && ! shopt -oq posix; then # . /etc/bash_completion #fi
export PATH=/root/anaconda3/bin:$PATH
# >>> conda initialize >>> # !! Contents within this block are managed by 'conda init' !! __conda_setup="$('/root/anaconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)" if [ $? -eq 0 ]; then eval"$__conda_setup" else if [ -f "/root/anaconda3/etc/profile.d/conda.sh" ]; then . "/root/anaconda3/etc/profile.d/conda.sh" else export PATH="/root/anaconda3/bin:$PATH" fi fi unset __conda_setup # <<< conda initialize <<<
# JINA_CLI_BEGIN
## autocomplete _jina() { COMPREPLY=() local word="${COMP_WORDS[COMP_CWORD]}"
if [ "$COMP_CWORD" -eq 1 ]; then COMPREPLY=( $(compgen -W "$(jina commands)" -- "$word") ) else local words=("${COMP_WORDS[@]}") unset words[0] unset words[$COMP_CWORD] local completions=$(jina completions "${words[@]}") COMPREPLY=( $(compgen -W "$completions" -- "$word") ) fi }
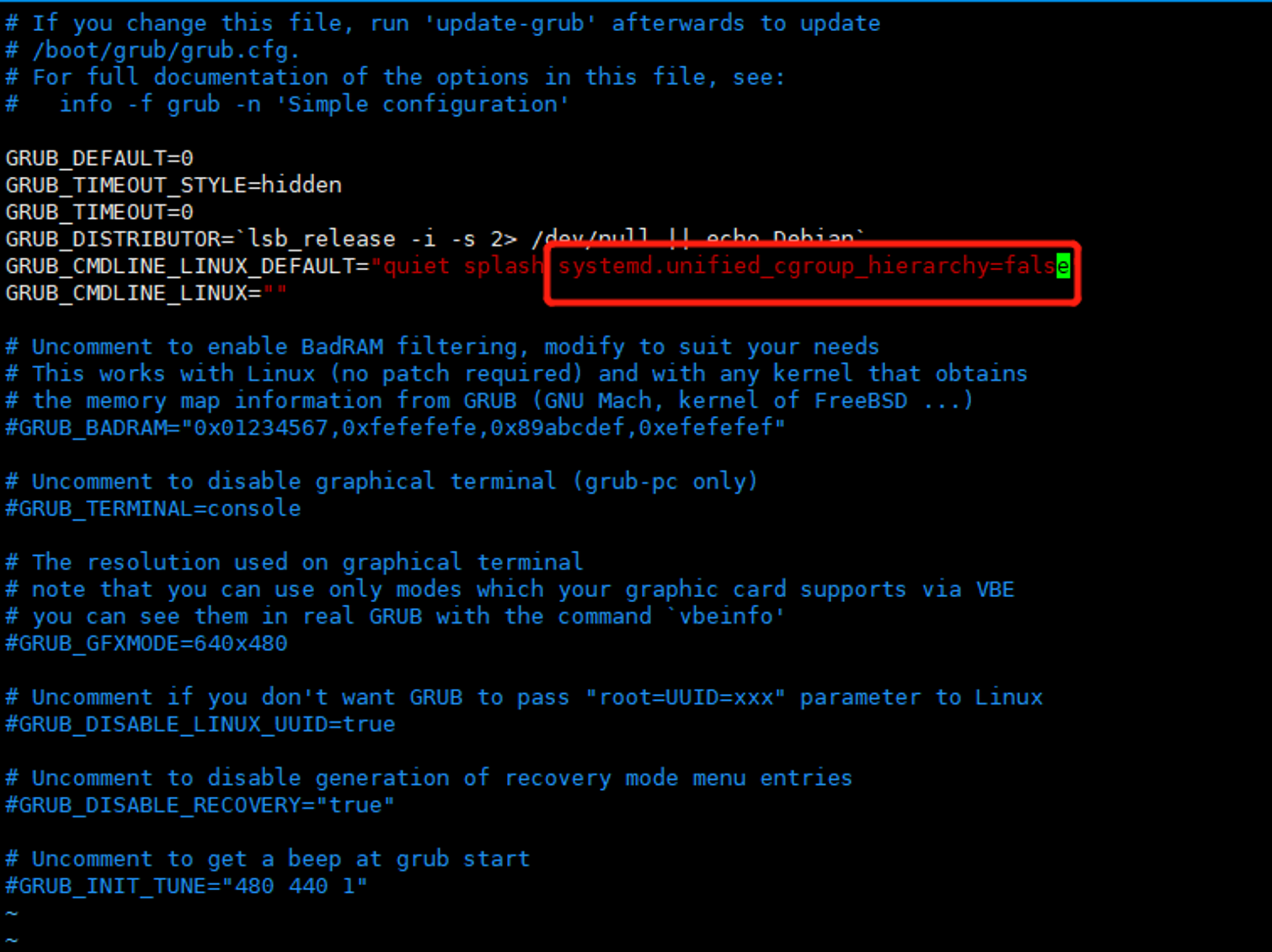
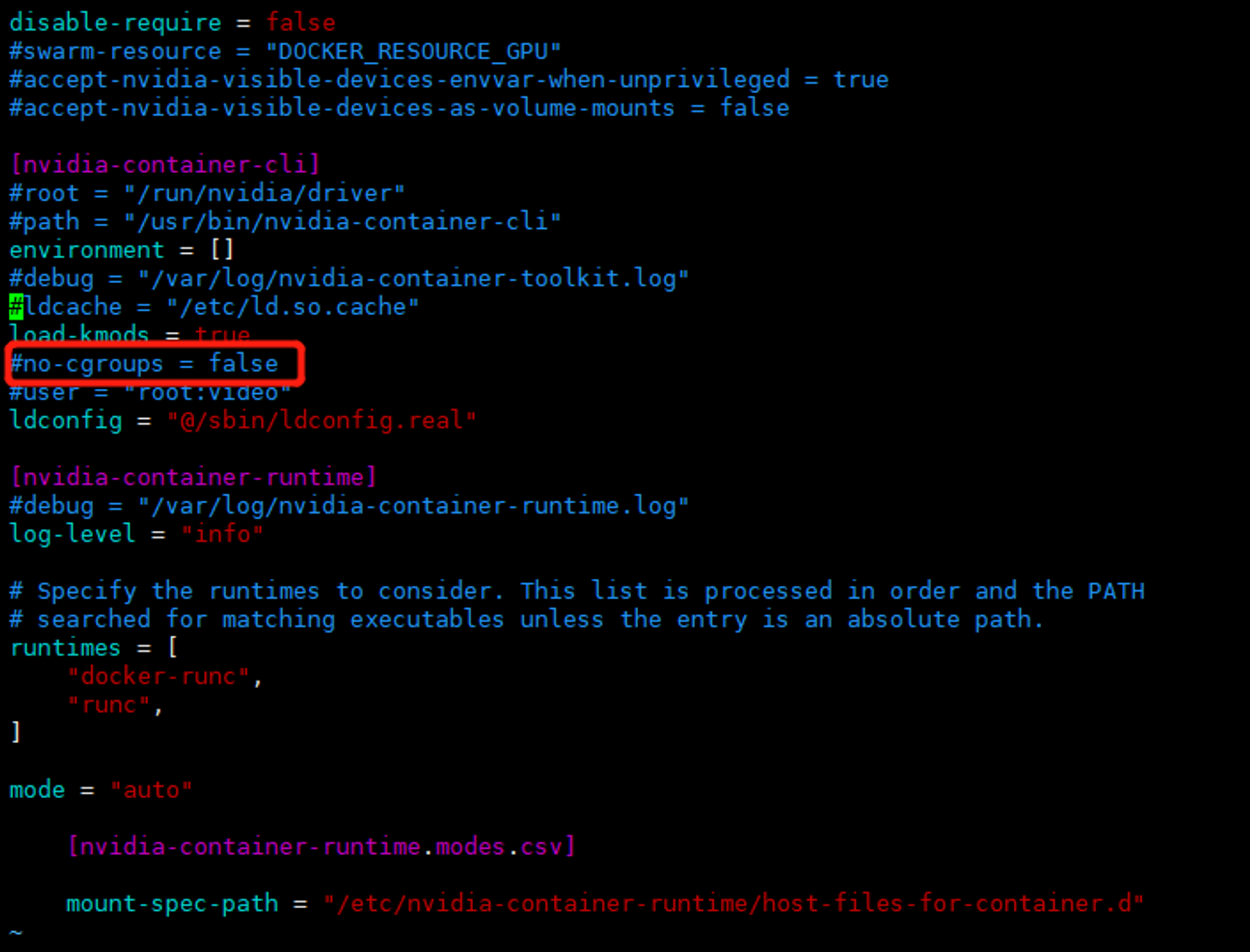
Note: libnvidia-containerAUR has no support for cgroups v2. You need to set the systemd.unified_cgroup_hierarchy=false kernel parameter and set no-cgroups = false in /etc/nvidia-container-runtime/config.toml if you are using systemd v248 or higher.