MinerU 介绍
背景介绍
处理监管文档会遇到一个比较操蛋的问题就是部分文档只有pdf格式的,并且pdf是扫描版本的,无法直接读取pdf,利用多模态进行处理,目前口袋有比较紧张,最近发现一个宝藏项目,MinerU,子项目(PDF-Extract-Kit),可以识别pdf,将pdf转成md,方便数据处理和LLM进行对话。
介绍
MinerU 是一款一站式、开源、高质量的数据提取工具,主要包含以下功能:
- Magic-PDF PDF文档提取
- Magic-Doc 网页与电子书提取
这里主要介绍Magic-PDF,Magic-PDF是一款将 PDF 转化为 markdown 格式的工具。支持转换本地文档或者位于支持S3协议对象存储上的文件。
主要功能包含
- 支持多种前端模型输入
- 删除页眉、页脚、脚注、页码等元素
- 符合人类阅读顺序的排版格式
- 保留原文档的结构和格式,包括标题、段落、列表等
- 提取图像和表格并在markdown中展示
- 将公式转换成latex
- 乱码PDF自动识别并转换
- 支持cpu和gpu环境
- 支持windows/linux/mac平台
安装
1
2
| conda create -n mineru python=3.10
conda activate mineru
|
1.安装依赖
完整功能包依赖detectron2,该库需要编译安装,如需自行编译,请参考 facebookresearch/detectron2#5114
或是直接使用作者预编译的whl包:
1
| pip install detectron2 --extra-index-url https://wheels.myhloli.com -i https://pypi.tuna.tsinghua.edu.cn/simple
|
2.使用pip安装完整功能包
1
| pip install magic-pdf[full]==0.6.2b1 -i https://pypi.tuna.tsinghua.edu.cn/simple
|
3.下载模型权重文件
1
| git clone https://www.modelscope.cn/wanderkid/PDF-Extract-Kit.git
|
4. 拷贝配置文件并进行配置
在仓库根目录可以获得 magic-pdf.template.json 配置模版文件
1
| cp magic-pdf.template.json ~/magic-pdf.json
|
使用cuda
1
2
3
4
5
6
7
8
9
10
11
12
13
| {
"bucket_info":{
"bucket-name-1":["ak", "sk", "endpoint"],
"bucket-name-2":["ak", "sk", "endpoint"]
},
"models-dir":"/data/models",
"device-mode":"cuda",
"table-config": {
"is_table_recog_enable": false,
"max_time": 400
}
}
|
这里有个小坑,从huggingface下载下来的模型目录为:/data/models/PDF-Extract-Kit/,此处配置为:/data/models/PDF-Extract-Kit/models/ ,另外目前不支持多卡配置。
使用
1. 通过命令行使用
直接使用
1
| magic-pdf pdf-command --pdf "pdf_path" --inside_model true
|
程序运行完成后,你可以在”/tmp/magic-pdf”目录下看到生成的markdown文件,markdown目录中可以找到对应的xxx_model.json文件
如果您有意对后处理pipeline进行二次开发,可以使用命令
1
| magic-pdf pdf-command --pdf "pdf_path" --model "model_json_path"
|
这样就不需要重跑模型数据,调试起来更方便
更多用法
2. 通过接口调用
本地使用
1
2
3
4
5
6
7
| image_writer = DiskReaderWriter(local_image_dir)
image_dir = str(os.path.basename(local_image_dir))
jso_useful_key = {"_pdf_type": "", "model_list": model_json}
pipe = UNIPipe(pdf_bytes, jso_useful_key, image_writer)
pipe.pipe_classify()
pipe.pipe_parse()
md_content = pipe.pipe_mk_markdown(image_dir, drop_mode="none")
|
在对象存储上使用
1
2
3
4
5
6
7
8
9
| s3pdf_cli = S3ReaderWriter(pdf_ak, pdf_sk, pdf_endpoint)
image_dir = "s3://img_bucket/"
s3image_cli = S3ReaderWriter(img_ak, img_sk, img_endpoint, parent_path=image_dir)
pdf_bytes = s3pdf_cli.read(s3_pdf_path, mode=s3pdf_cli.MODE_BIN)
jso_useful_key = {"_pdf_type": "", "model_list": model_json}
pipe = UNIPipe(pdf_bytes, jso_useful_key, s3image_cli)
pipe.pipe_classify()
pipe.pipe_parse()
md_content = pipe.pipe_mk_markdown(image_dir, drop_mode="none")
|
本地命令执行效果如下:
1
| magic-pdf pdf-command --pdf ../PDF-Extract-Kit/inputs/18.4《信息安全技术\ \ 安全漏洞标识与描述规范》GB_T\ 28458-2012.pdf --inside_model true
|

成功

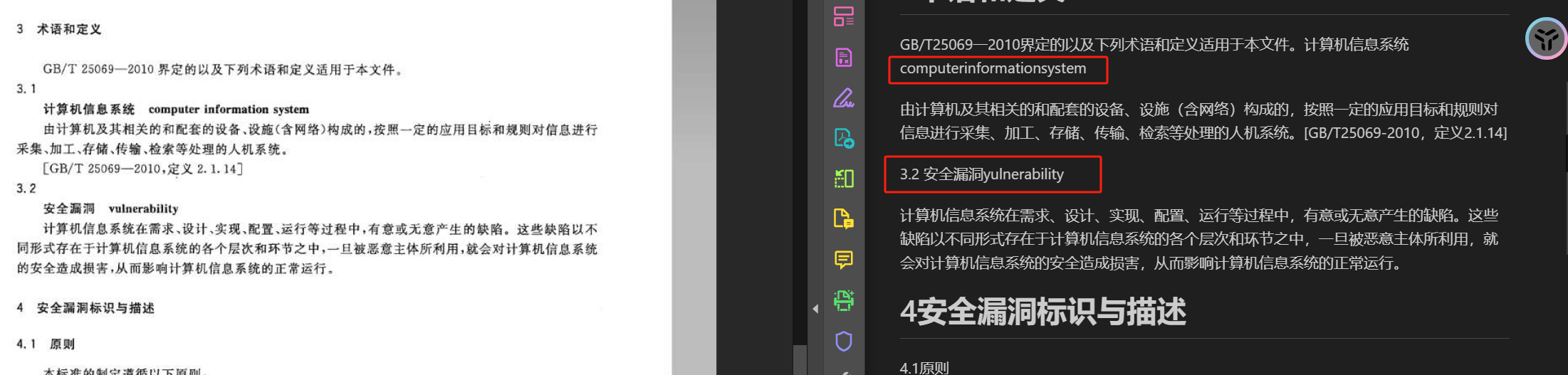
效果对比
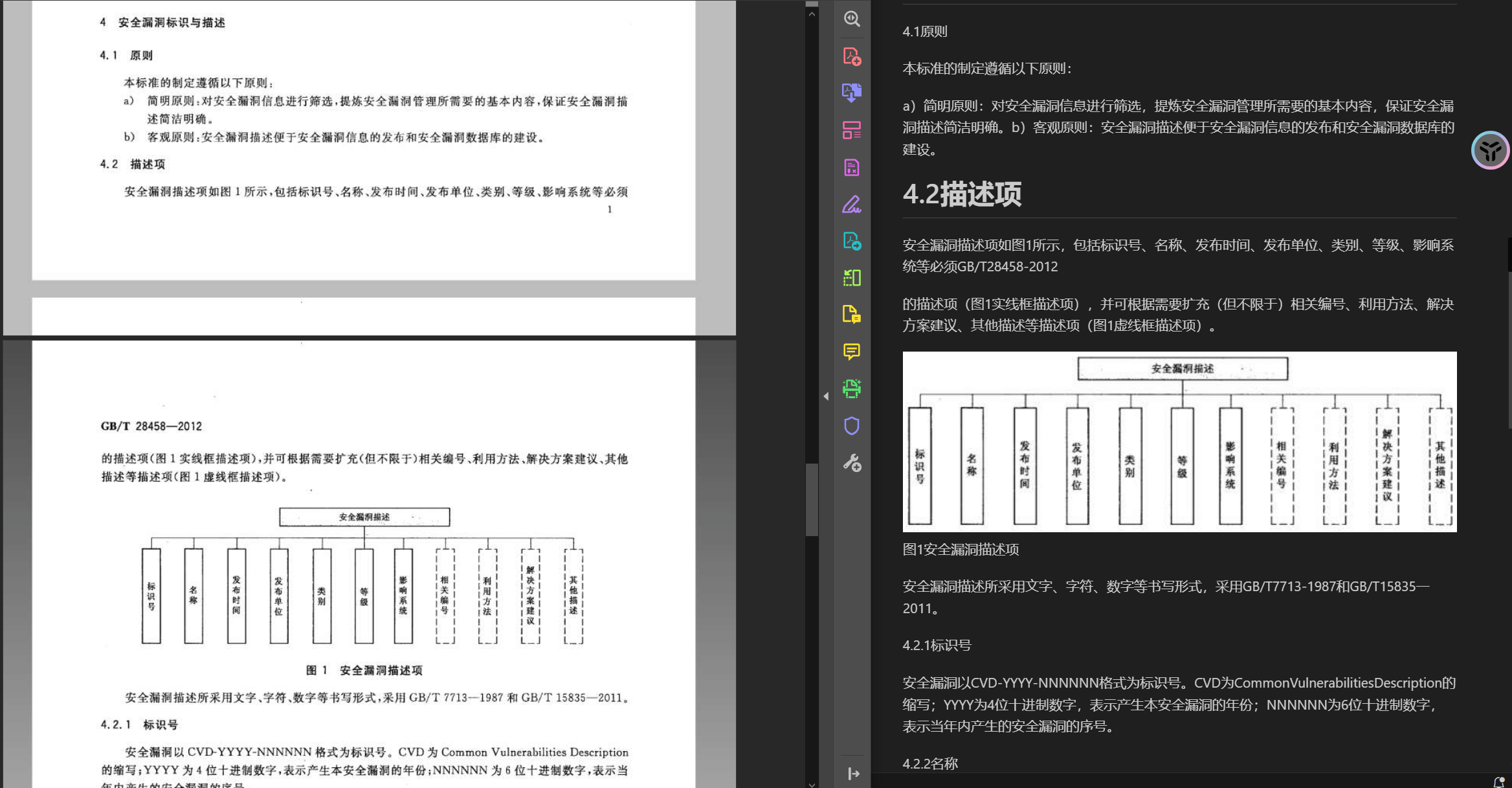
部分识别错误,但是整体已经很经验
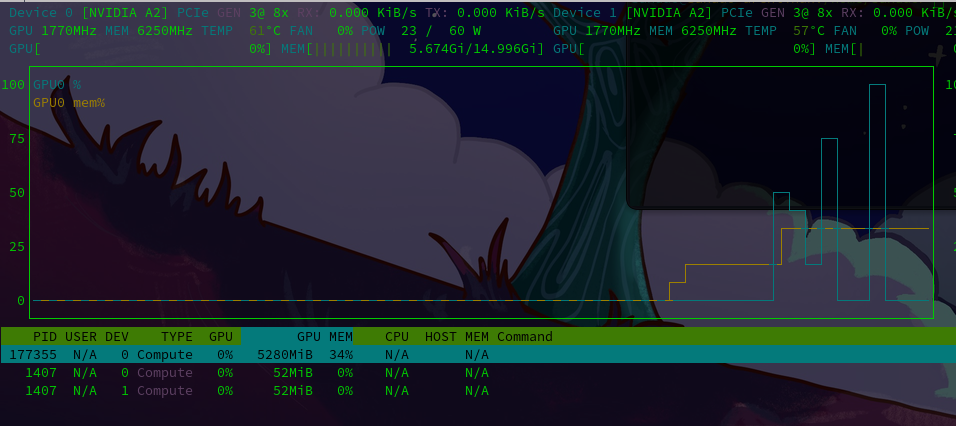
GPU资源占用效率如下:
结论
1、开源项目中,目前MinerU可以满足pdf自动化识别需求,方便数据的整理和收集。
2、由于ocr识别过程中仍会存在个别识别失误,格式混乱问题,如果项目数据要求比较准确,需要慎重考虑
3、MinerU的命令行设计的有些反人类,这个属于个人观点
错误
ValueError: Unable to avoid copy while creating an array as requested.

参考