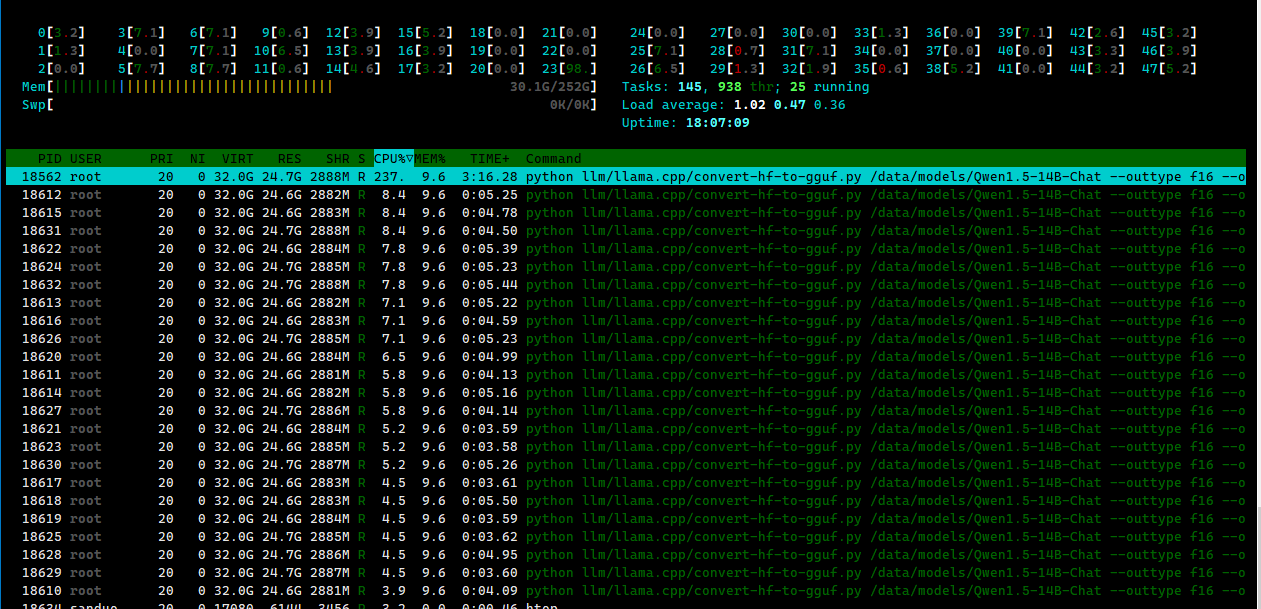
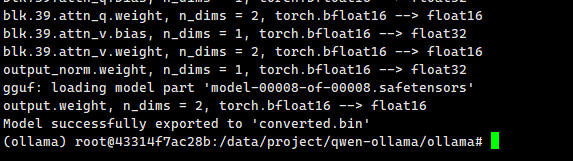
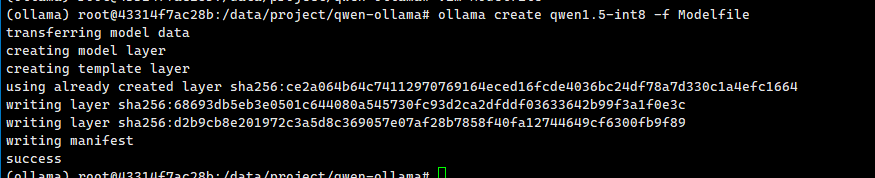
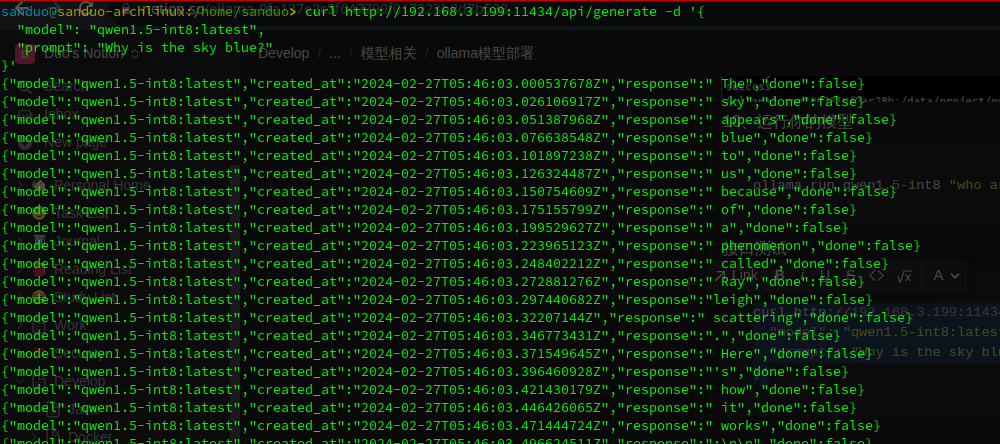
Loadingmodel: Qwen1.5-14B-Chat-GPTQ-Int8 gguf: ThisGGUF file is forLittleEndian only Set model parameters Set model tokenizer Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained. gguf: Adding151387merge(s). gguf: Setting special token type eos to 151643 gguf: Setting special token type pad to 151643 gguf: Setting special token type bos to 151643 gguf: Setting chat_template to {% for message in messages %}{{'<|im_start|>' + message['role'] + ' ' + message['content'] + '<|im_end|>' + ' '}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant ' }}{% endif %} Exporting model to 'converted.bin' gguf: loading model part 'model-00001-of-00005.safetensors' token_embd.weight, n_dims = 2, torch.float16 --> float16 blk.0.attn_norm.weight, n_dims = 1, torch.float16 --> float32 blk.0.ffn_down.bias, n_dims = 1, torch.float16 --> float32 Can not map tensor 'model.layers.0.mlp.down_proj.g_idx'
尝试使用无量化模型Qwen1.5-14B-Chat
错误,这个原因是由于镜像内未安装git-lfs
1 2 3 4 5 6 7 8 9 10 11 12 13
gguf: loading model part 'model-00001-of-00008.safetensors' Traceback (most recent call last): File"/data/project/qwen-ollama/ollama/llm/llama.cpp/convert-hf-to-gguf.py", line 1937, in <module> main() File"/data/project/qwen-ollama/ollama/llm/llama.cpp/convert-hf-to-gguf.py", line 1931, in main model_instance.write() File"/data/project/qwen-ollama/ollama/llm/llama.cpp/convert-hf-to-gguf.py", line 152, in write self.write_tensors() File"/data/project/qwen-ollama/ollama/llm/llama.cpp/convert-hf-to-gguf.py", line 113, in write_tensors for name, data_torch in self.get_tensors(): File"/data/project/qwen-ollama/ollama/llm/llama.cpp/convert-hf-to-gguf.py", line 71, in get_tensors ctx = cast(ContextManager[Any], safe_open(self.dir_model / part_name, framework="pt", device="cpu")) safetensors_rust.SafetensorError: Errorwhile deserializing header: HeaderTooLarge