敏捷代码审计之代码硬编码
敏捷代码审计之代码硬编码
介绍
硬编码(英语:Hard Code或Hard Coding)是指在软件编码过程中,将输出或输入的相关参数(例如:路径、输出的形式或格式)直接以常量的方式撰写在源代码中,而非在执行期间由外界指定的设置、资源、资料或格式做出适当回应。一般被认定是种反模式或不完美的实现,因为软件受到输入资料或输出格式的改变就必须修改源代码,对客户而言,改变源代码之外的小设置也许还比较容易。但硬编码的状况也并非完全只有缺陷,因某些封装需要或软件本身的保护措施,有时是必要的手段。除此之外,有时候因应某些特殊的需求,制作出简单的应用程序,应用程序可能只会执行一次或者有限的几次,或者永远只应付某种单一需求。
所谓硬编码,就是把一个本来应该(可以)写到配置信息中的信息直接在程序代码中写死了。密钥硬编码在代码中,而根据密钥的用途不同,这导致了不同的安全风险,有的导致加密数据被破解,数据不再保密,有的导致和服务器通信的加签被破解,引发各种血案。
硬编码检测方法
方法论主要参考:密码密钥硬编码检查,参考链接详见文章末尾。
鉴别密码密钥方法
香农熵(Shannon entropy)
密钥的长度决定了密钥空间(keyspace),通常以位为单位。密钥空间越大,密钥被攻破的难度就越大。
密钥是由密钥空间的随机值构成。对于任意一个随机变量 X,它的熵定义如下:
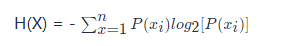
变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。
P(x_i)P(xi) : 指的是单个样本变量所属的变量种类的个数占据所有变量个数的比例。同等长度的字符串,通常密钥的熵值更高
密钥为避免彩虹攻击,在取值上更加的离散,会尽量采用不重复的字符。就像我们为了增加密码的复杂性,要求长度不小于8,必须包含大小写、特殊字符、以及数字一样的道理。所以密钥的熵值会比一般的文本要高的多。我们就是利用这点来识别字符串是否是密钥。
工具的检查逻辑
对于密码密钥的硬编码检查可以采用静态分析工具来完成。工具的检查过程通常包含四个过程:输入文件准备、检查、过滤和报告输出。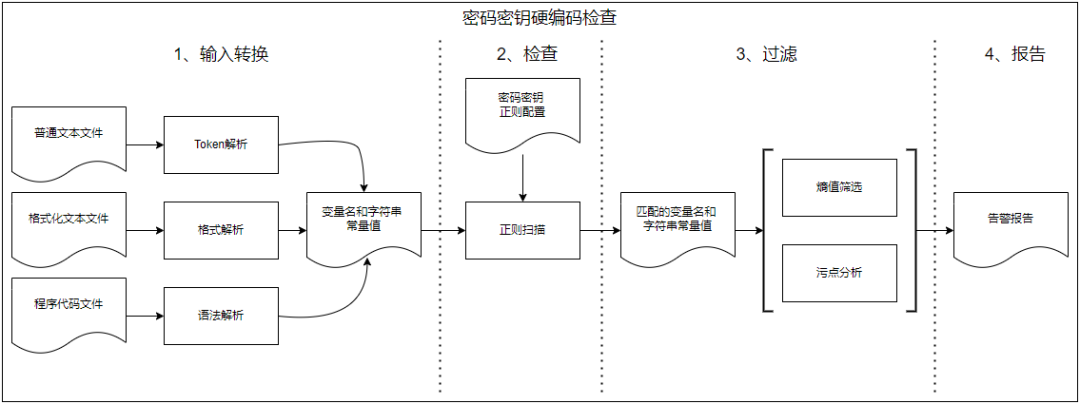
输入文件转换
输入文件分类
我们需要检查的文本文件进行分类,通常包括以下几种类型:- 程序语言:C、C++、Java、Python、Go、Js等;
- 有统一格式的文件:属性文件、yaml、csv、json、xml等;
- 文本文件:没有固定格式的文本文件。
分类的目的是为了更好的识别文件中的字符串常量,充分利用字符串常量的上下文关联,以便在分析中最大程度的减少误报。
- 输入文件转换
- 程序语言:通过各语言的语法解析器,解析成抽象语法树,提取语法树中的等于字符串的常量,以及对
- 应的变量名;有统一格式的文件:照格式转换成变量名和字符串常量值;
- 文本文件:采用token的方式分割成一个个的token,变成一个各的字符串常量。
密码密钥检查
在我们得到大量的变量名和字符串常量后,主要通过正则表达式匹配的方式完成目标的筛选。我们收集的密钥格式包括国内国外主流平台、SDK等相关系统的密钥配置参数名称,可以根据客户的实际情况手动增加和优化规则,进而提高检测的速度和效率。
由于检查密码密钥的种类和类型不同,可以通过配置文件来提高检查能力的可扩展性。
检查配置选项主要包括以下内容:
| 信息 | 描述 |
|---|---|
| 检查类型 | 可分为:变量名、字符串常量、或两个都检查 |
| 密码密钥的类型 | 用于区分不同类型的密码密钥;同时用于告警时区分具体检测到的密码密钥类型 |
| 正则表达式 | 主要设定匹配的长度,每个字符的可选类型 |
| 熵值的阈值 | 用于精确的识别密码密钥的类型,降低误报 |
例如:
检查硬编码的口令:检查变量名中包含:password、passwd、pwd的变量,且变量等于字符串常量;正则表达式可以设置成为:”.*(password|passwd|pwd)$”。
检查GitHub的个人凭证:检查字符串常量;这个凭证是以”ghp_”开头的,跟随长度为36的字符串,且每个字符可以为数字和字母;正则表达式可以设置成为:“ghp_[0-9a-zA-Z]{36}”。
密码密钥过滤
静态分析能很大程度上减少了人工审核的工作量,但由于检查模式的不确定性,也会带来不少的误报。误报会给用户在审核过程中带来很大的负面情绪,从而不愿继续使用工具。为了进一步降低误报,我们可以通过下面的方式来降低误报:
密码密钥熵值的计算
前面讨论过密码密钥的特点,可以通过检测密码密钥的信息熵的方式来降低误报。有些密码密钥设定了最低的阈值,但还是有很多密码密钥并未给出具体的阈值,这个就需要通过经验积累来设定,目前业界也有通过机器学习来完善这个阈值的设定。
污点分析
在代码中,对于口令的变量的取名上,很多并不会遵守可读性和可维护性来设定变量名,通过前面正则表达式的方式来查找硬编码密码的方式,会造成很多的漏报。这里还可以通过污点分析的方法,来推导出密码是否采用了硬编码。例如检查jdbc连接的密码参数,查看该参数是否为字符串常量。
报告输出
将经过过滤后的结果,输出告警,给出可能泄露的文件名和变量或可能为密码密钥的常量字符串位置,便于人工的排查。
硬编码检测实战
对于审计人员或者安全管理人员并不需要关注密钥检查的算法,通常只需要选用合适的流程,匹配恰当的工具,迅速准确的定位硬编码即可。
检查的流程
信息收集:此阶段中,审计人员进行必要的信息收集,包括本次审计要求、稳定版本的源代码。
工具审计:确定工具审计的标准和各项配置参数,使用Fortify、gitleaks等工具检测目标源代码,对工具检测的结果进行人工核查,筛选,分析,汇总。
人工审计:对客户要求人工审计的重点代码采用人工分析的方法,对源代码中的硬编码进行审计。
综合汇总:将工具审计和人工审计的结果进行对比汇总
输出报告:此阶段中,审计人员根据测试的结果编写直观的硬编码审计服务报告。
源代码硬编码审计要求工作人员有丰富的经验及新颖的思路,同时也是一项比较耗费时间和资源的工作,从效率考虑,一般选择性的抽取部分重要环节的代码进行人工审计。
开源检查工具
SecretScanner
项目地址:https://github.com/deepfence/SecretScanner
SecretScanner可以扫描主机上的容器镜像或本地目录,主要通过正则匹配,扫描效率较高,不仅支持代码而且支持容器扫描,并将结果输出到JSON文件,其中会包含SecretScanner找到的所有敏感数据的详细信息。
SecretScanner方便安全人员在主机上收集敏感数据,如果需要审计特定类型代码或者增加新的硬编码检测点,需要手动修改规则,默认配置文件位于项目中的config.yaml,可以根据实际情况自行修改。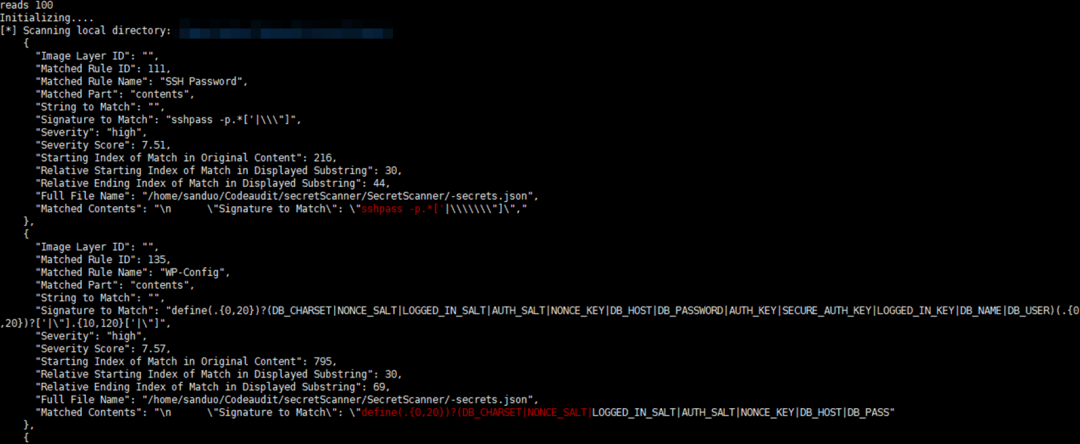
不足:规则数量一般
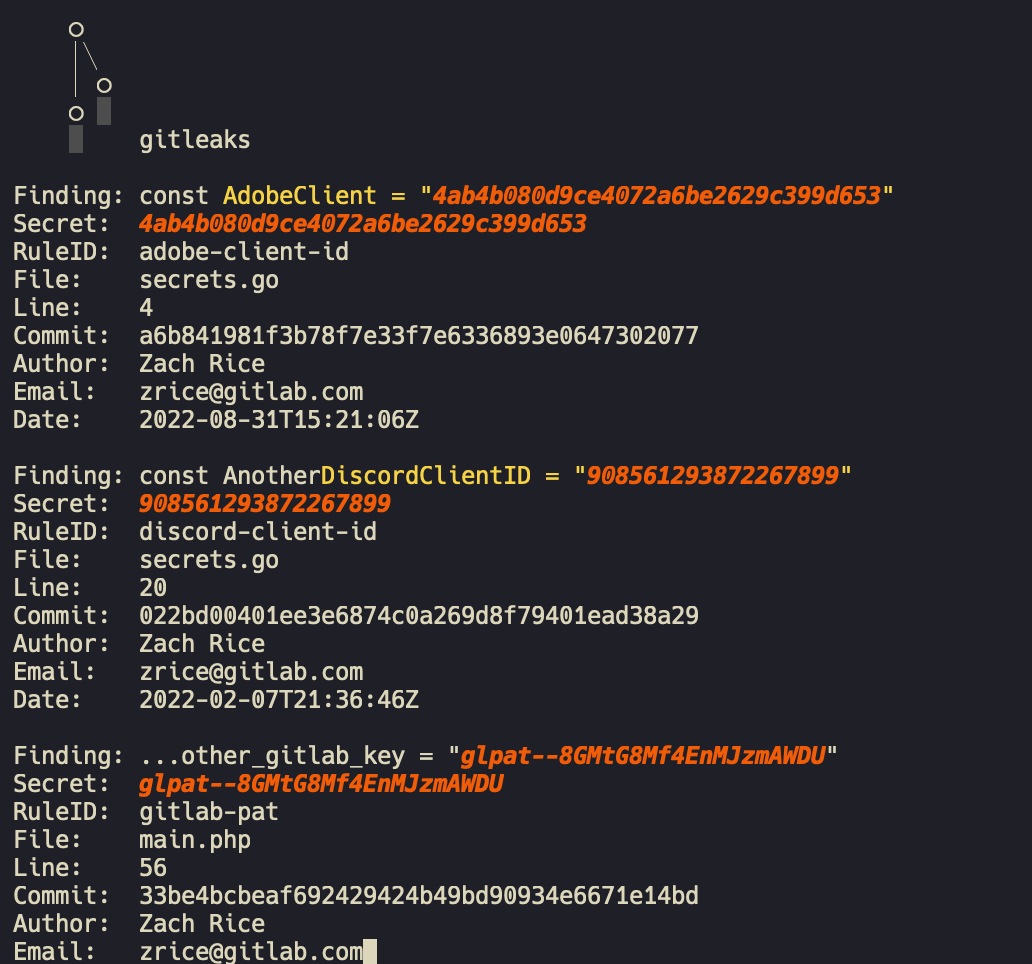
gitleaks
Gitleaks为你提供了一种方法来扫描你的git存储库,以查找这些不需要的数据,这些数据应该是私有的,扫描可以自动化,以完全适合CI/CD工作流程,以便在密码识别更深入到代码库之前进行识别。
gitleaks比较有趣的有以下几点:
- 支持私有存储库扫描以及需要基于密钥的身份验证的存储库。
- 支持Gitlab批量组织和存储库所有者(用户)存储库扫描,并提取请求扫描以在常见CI工作流中使用。
- 支持Pre-Commit,方便研发人员在提交之前进行硬编码检测,防止敏感信息提交。
- 支持使用git log命令验证由gitleaks找到的发现
不足:对普通用户友好程度一般,对于pre-commit需要手动配置,并且在大文件扫描效率较低,官方已移除多线程配置参数,使用默认线程数进行扫描,如果在使用过程中感觉缓慢,可自行设定编译。同样规则数量一般,可以根据实际情况添加。
SASTs
各种SAST工具都可以检测硬编码,但是受限于使用场景,只能检测较少的硬编码场景,比如password,key等,对于特定的硬编码需要手动增加规则,规则友好性一般。
硬编码检测规则
无论gitleaks还是secretScanner,均使用正则匹配相关硬编码,敏感信息,我这里整理出部分敏感信息参数,供大家参考,至于规则,按照要求,自行补充即可,比较简单,这里就不单独描述了
1 | |
参考:
- https://developer.huawei.com/consumer/cn/forum/topic/0204931065040020698?fid=0101592429757310384【密码密钥硬编码检查】
- https://github.com/deepfence/SecretScanner【SecretScanner】
- https://github.com/zricethezav/gitleaks【gitleaks】
- https://wooyun.js.org/drops/Android%E5%AE%89%E5%85%A8%E5%BC%80%E5%8F%91%E4%B9%8B%E6%B5%85%E8%B0%88%E5%AF%86%E9%92%A5%E7%A1%AC%E7%BC%96%E7%A0%81.html【浅谈密钥硬编码】
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!